Efficient Strategies for Large-Scale RDBMS Data Migration: Optimising Insertions, Updates, and Deletes with MySQL
Data migration is a critical aspect of managing and evolving relational database management systems (RDBMS). It involves transferring data from one location to another, either within the same database or outside of it. Whether you are reorganizing your database structure, upgrading to a new system, or consolidating data from multiple sources, a well-executed data migration process is crucial for maintaining data integrity and ensuring uninterrupted operations.
When it comes to RDBMS data migration, there are two primary scenarios to consider: migration within the database and migration outside the database. Each scenario presents its own set of challenges and criticalities that must be carefully addressed to achieve a successful outcome.
Migrating data within the database involves transforming and transferring data from one table to another or from one schema to another within the same RDBMS. This could include tasks such as reorganizing data to improve performance, modifying the database schema to accommodate new requirements, or consolidating data from multiple tables. The criticalities involved in this type of migration include maintaining data consistency, ensuring referential integrity, and optimizing the database structure to enhance performance.
On the other hand, migrating data outside the database typically involves transferring data between different database systems or even across different platforms. This type of migration could occur when upgrading to a new RDBMS, switching vendors, or migrating data to the cloud. The criticalities here revolve around ensuring data accuracy and completeness during the transfer, preserving data relationships, and managing potential compatibility issues between different database systems.
In both scenarios, proper planning, analysis, and execution are essential to mitigate risks and achieve a successful data migration. Factors such as data cleansing, schema optimization, performance monitoring, and backup strategies play crucial roles in ensuring the integrity, reliability, and consistency of the migrated data.
In this blog, we will explore the various optimizations and steps required to handle large-scale RDBMS data migrations using MySQL as the target database. By understanding and implementing these strategies, you can navigate the complexities of data migration and ensure a seamless transition while preserving the integrity of your valuable data.
- Optimising Inserts
- Optimising Updates
- Optimising Deletes
- Footnotes
Optimising Inserts
When performing a large-scale data migration in a relational database management system (RDBMS) using MySQL, optimizing the insertion of data is crucial for efficient and timely migration. The process of inserting data can be resource-intensive, and without proper optimization techniques, it can result in slow performance and increased downtime. In this section, we will explore various strategies to optimize data insertion, such as batch inserts and index management. By implementing these optimisation techniques, you can significantly improve the speed and efficiency of data insertion during the migration process.
Insert Data in Batches:
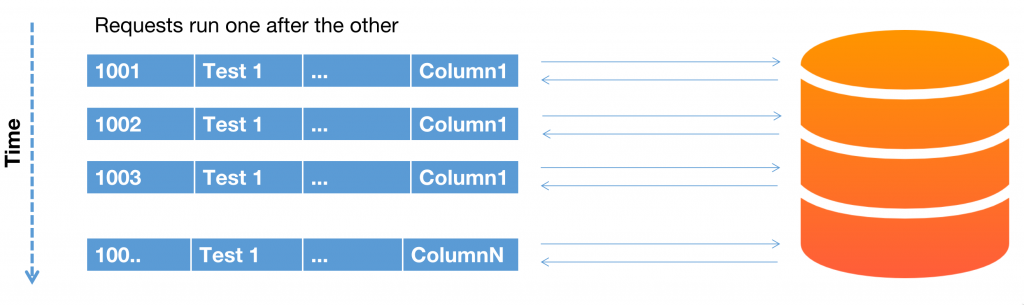
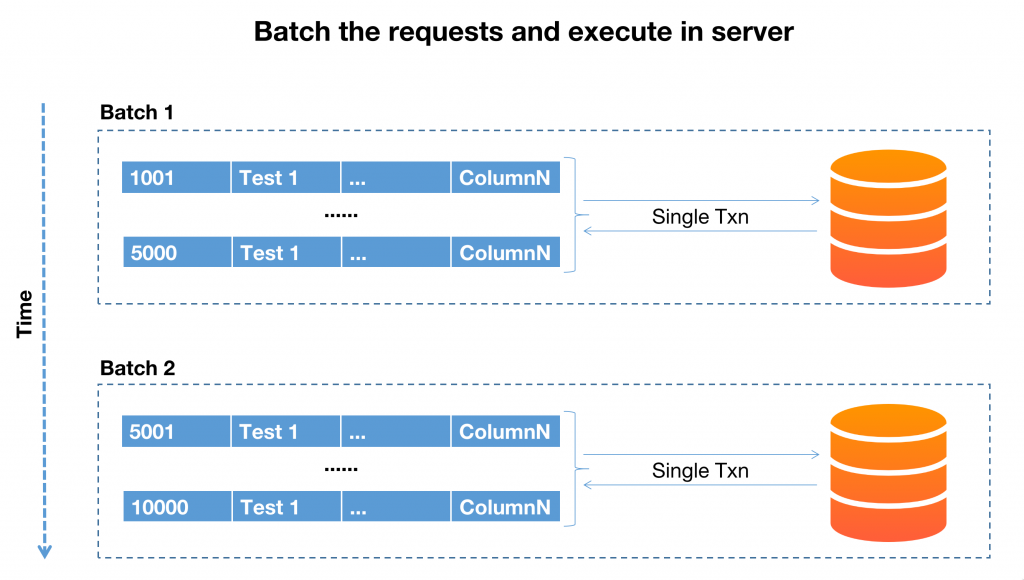
Instead of inserting data row by row, consider inserting data in batches. The batch size should be determined through trial runs and performance testing, as the optimal batch size can vary depending on factors such as the size of the dataset, hardware capabilities, and database configuration. Experiment with different batch sizes to find the balance between throughput and resource utilisation.
Running one by one
Running in batches
Disable Indexes:
Dropping or disabling indexes before inserting data can speed up the insertion process. Indexes need to be updated for each new row inserted, which can significantly slow down bulk data insertion. By temporarily disabling or dropping the indexes, the database engine can focus solely on the insertion process, improving performance. However, this approach is suitable when you are inserting a large amount of data in bulk. If you are inserting smaller amounts of data or frequent individual inserts, it might be better to keep the indexes enabled.
DROP INDEX `index_name` ON `table_name`;
Recreate Indexes After Bulk Insertion:
Once the data insertion is complete, it is crucial to recreate the indexes to ensure optimal query performance. After disabling or dropping the indexes, recreate them using the appropriate syntax provided by the database engine. This allows the database engine to build the indexes based on the inserted data in an optimized manner. Consider creating the indexes after data insertion is complete to avoid the overhead of index maintenance during the insertion process.
Utilize Bulk Insert Statements:
Instead of using individual INSERT statements, utilize bulk insert statements provided by the database engine, such as MySQL’s INSERT INTO … VALUES (), (), () syntax. This allows you to insert multiple rows in a single statement, reducing the overhead of parsing and executing individual statements. Bulk insert statements are generally more efficient and can significantly improve the speed of data insertion.
Consider Partitioning the Table:
If the table being migrated is extremely large and the database supports table partitioning, consider partitioning the table based on a specific criterion, such as range or list partitioning. Partitioning allows you to divide the table into smaller, more manageable segments, which can improve data insertion performance by distributing the load across multiple disk drives or storage devices.
https://dev.mysql.com/doc/refman/8.0/en/partitioning.html
Optimize Database Configuration:
Ensure that the database server is configured properly for efficient data insertion. Adjust relevant settings such as buffer sizes, cache settings, and transaction log settings to optimize the insertion process. Fine-tuning these configurations can significantly enhance the performance of data insertion operations.
Increase Memory Allocation:
Set the innodb_buffer_pool_size parameter in the MySQL configuration file (my.cnf) to allocate an appropriate amount of memory for the InnoDB buffer pool. For example: innodb_buffer_pool_size = 4G.
Adjust Buffer Pool Size:
Similar to the previous point, configure the innodb_buffer_pool_size parameter to increase the size of the buffer pool. A recommended value is typically 70-80% of the available memory on the server.
Optimize Disk Configuration:
Ensure that the MySQL data directory is placed on a fast and reliable storage device. Consider using RAID configurations or SSDs for improved read and write performance.
Configure Logging Options:
Adjust the MySQL logging options based on your requirements. For example, set the log_error parameter to specify the error log file path and name. You can also adjust the general_log and slow_query_log parameters to enable or disable general query logging and slow query logging, respectively.
Tune Query Cache:
Enable the query cache by setting the query_cache_type parameter to ON and configure the query_cache_size parameter to allocate an appropriate amount of memory for the query cache. For example: query_cache_size = 256M
Adjust Connection Pooling:
Configure the max_connections parameter to set the maximum number of concurrent connections allowed. Additionally, adjust the wait_timeout and max_allowed_packet parameters to optimize connection handling and prevent resource exhaustion.
Review and Optimize Indexes:
Analyze the query patterns and use the EXPLAIN statement to identify inefficient queries that may require index optimization. Create or modify indexes based on the identified queries to improve query performance. Ensure that primary keys and foreign keys are properly indexed.
Update Database Statistics:
Run the ANALYZE TABLE command or use the OPTIMIZE TABLE command to update database statistics and ensure the query optimizer has accurate information for query planning
NOTE; if you are using AWS RDS, you won’t be having direct access to the my.cnf file. In this case you can make the necessary updates through the paramter_group or the option_group.
Optimising Updates
When it comes to updates, they share similarities with inserts in terms of their operations. One optimization technique is to drop indexes before performing updates to enhance speed. However, it is important to be cautious and retain the index for any field used in WHERE conditions or joins. This ensures efficient data retrieval when filtering or joining records.
Additionally, batching updates can significantly improve performance compared to executing individual updates or attempting to update all records at once. By grouping updates into batches, the update process becomes faster and more efficient.
To clarify:
- Drop indexes before updates, but retain indexes for fields used in WHERE conditions or joins.
- Batching updates leads to faster performance compared to individual or bulk updates.
By implementing these optimisation techniques, you can improve the efficiency of update operations while maintaining the necessary indexes for effective data retrieval and ensuring timely updates to the database.
Optimising Deletes
When it comes to bulk deletion in a database, optimizing the process can help improve performance and efficiency. Here are some points to consider:
Truncate the Entire Table:
If you need to delete all the records in a table, using the TRUNCATE statement is generally more efficient than using DELETE. TRUNCATE removes all the data from the table, resulting in faster deletion because it doesn’t generate individual delete statements for each row. However, keep in mind that TRUNCATE is a DDL (Data Definition Language) statement and cannot be rolled back. It also resets auto-increment counters and removes the table’s structure.
Handling Foreign Key Constraints:
When using TRUNCATE, foreign key constraints can pose challenges. If the table being truncated has foreign key relationships with other tables, TRUNCATE can fail due to referential integrity constraints. Even if you truncate the child table first and then attempt to truncate the parent table, the foreign key constraint can still cause a failure.
Temporarily Disabling Foreign Key Checks ( Caution ! ):
In scenarios where you need to truncate a parent table that has foreign key constraints, and you have already truncated the child table, you can temporarily disable foreign key checks to perform the truncation. The steps involve setting the FOREIGN_KEY_CHECKS variable to 0, truncating the child table, truncating the parent table, and then setting FOREIGN_KEY_CHECKS back to 1.
SET FOREIGN_KEY_CHECKS =0; TRUNCATE child_table1; TRUNCATE parent_table2; SET FOREIGN_KEY_CHECKS =1;
However, it’s important to note that using this approach can create data inconsistencies and dangling entries in the child table, leading to potential issues with data integrity. It is generally advised to avoid this method unless you have a specific requirement and understand the potential consequences.
Best Practices for Database Deletion:
Here are some additional best practices to consider for database deletion operations:
Evaluate Data Retention Policies:
Before deleting data, review data retention policies and ensure compliance with legal, regulatory, or business requirements. Identify any data that needs to be preserved for audit purposes or historical analysis and exclude it from the deletion process.
Use DELETE Statement with Proper Filtering:
When deleting specific records from a table, use the DELETE statement with appropriate filtering conditions to target only the desired data. Be cautious when using broad or unfiltered deletion operations, as they can unintentionally remove more data than intended.
You will regret a command like below
DELETE FROM `main-db`.CUSTOMERS
Instead, use conditions or limits
DELETE FROM `main-db`.CUSTOMERS where <condition> [limit 1000]
Consider Cascading Deletion:
If your database supports cascading deletion, define appropriate cascading delete rules for foreign key relationships. This ensures that when a parent record is deleted, associated child records are automatically deleted as well, maintaining data integrity and preventing orphaned records.
Monitor and Optimize Performance:
Monitor the performance of deletion operations and identify any performance bottlenecks. Analyze the database schema, indexes, and query execution plans to ensure optimal performance. Make necessary adjustments such as adding indexes or optimizing queries to improve deletion speed.
Implement Transactional Safety Measures:
When performing bulk deletion operations, consider executing them within a transaction to ensure data consistency and provide the ability to roll back changes if necessary. This helps prevent data corruption and provides a safety net in case of errors during the deletion process.
-- Start the transaction before actual command start transaction; DELETE FROM `main-db`.CUSTOMERS where created_at > '2023-06-09 23:00:00' limit 1000; -- Validate the data and commit if correct commit; -- Rollback changes is something is wrong rollback;
Note that this is only advised if we are deleting a portion of manageable chunk of data. Transaction block may put lot of pressure on the db for a very large data set. Also, if you use the above method in a live db, it will generate lock on the table till you commit or rollback.
Backup Data Before Deletion:
Before executing bulk deletion operations, perform a backup of the relevant data to safeguard against accidental or irreversible deletions. Regular backups are essential for disaster recovery and can help restore data in case of unexpected issues or human errors.
Remember to thoroughly understand the implications and potential risks associated with database deletion operations. Always exercise caution and have proper backups and contingency plans in place to mitigate any unforeseen issues.
Footnotes
In conclusion, when performing a large-scale RDBMS data migration using MySQL, optimising data insertion, updates, and deletion operations is crucial for ensuring efficiency and maintaining data integrity. By employing techniques such as batch insertions, disabling and recreating indexes, utilising prepared statements, and optimising query performance, you can enhance the speed and performance of data migration. Additionally, considering factors like foreign key constraints, transactional safety, and proper backup strategies further contribute to a successful and smooth data migration process. By following these best practices, you can minimize downtime, improve performance, and ensure the accuracy and integrity of your data throughout the migration journey.





