Efficiently batch processing records from large table in Spring using peeking
It’s not uncommon for a production system to have a table with multi-million records and there would be a requirement for the application to process the records individually for a batch job. Now there are plenty of ways in which we can retrieve the data from table using JPA, but many methods (especially paginated) gets slower as we progress through the records irrespective of the optimizations that we can do in the application code. The real culprit here is the database. To understand the issue, we need to make sure that we know how the pagination works and how to get around fixing this. We will be looking at how we can efficiently process a huge number of records in a table efficiently.
Sample use case
For the purpose of example, let’s consider the following case
- Our customer table has got 10 million records.
- We need to retrieve all the active customers and send them an email ( or this could be any processing on the record )
- There is a spring boot application in Java that uses JPA for retrieving the records from db using pagination.
- The logic is simply that we would be maintaining a page index and size of say 100 records per page and then increment the page index for each time we want to fetch the records and JPA would generate the query for us.
You may consider a sample code like below:
int pageIndex = 0;
int size = 100;
while ( true ) {
// Create a PageRequest object that will be passed as Pageable interface to repo
PageRequest pageRequest = new PageRequest(pageIndex,size);
// Get the data from the database
List<Customer> customers = customerRepository.fetchRecords(pageRequest);
// Check if data is there
if ( customers == null || customers.isEmpty()) {
break;
}
// Do the processing
// Increment the pageIndex
pageIndex++;
}
Now let’s see what is happening at the database level ( For eg: Mysql ) when we execute the pagination query. It will generate a SQL like below :
-- First iteration ( pageIndex = 0, size = 100 ) select * from CUSTOMERS where status = 'ACTIVE' limit 0, 100; -- Second iteration ( pageIndex = 1, size = 100 ) select * from CUSTOMERS where status = 'ACTIVE' limit 100, 100; -- Second iteration ( pageIndex = 2, size = 100 ) select * from CUSTOMERS where status = 'ACTIVE' limit 200, 100;
As you can see, there are 2 values after the limit. First one is the offset value and the second one is the number of items to be retrieved starting from offset value.
- During the first iteration, there is no offsetting and hence it will take the first 100 records
- For the second iteration, we need to offset the first 100 records and then read the next 100 records
- and so on…
As you can see here the records are getting offset and this process is called offsetting. Here the DB need to read the records and skip them. So you can imagine that if we have already read the first 1 million records, for all the subsequent records, we need to read and skip 1 million records. This will dramatically slow down the fetch from the database for the queries after a certain number of records and would worsen towards the end. If we plot a graph with Y axis as the number of the records to skip and X-axis as the pageIndex with a record size of 100 per page, it would like below :
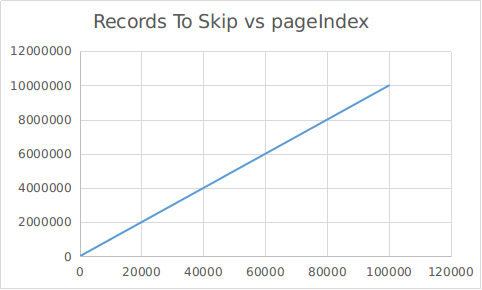
This would be the same if we plot time to fetch against the page Index. Hence you can see that the offset method is a very inefficient way of retrieving data from a large database and can affect the processing time a lot.
Peeking
That brings us to peeking. This does not include the offsetting/skipping of records, instead, we will be ordering and tracking a numerical unique identifier in the result and requesting for entries greater than the last unique entry. In this method, the SQL would be something like below ( assuming customer_id is the unique auto-generated identifier for the records )
-- First iteration ( size = 100, lastCustomerId = 0 ) select * from CUSTOMERS where status = 'ACTIVE' and customer_id > 0 order by customer_id asc limit 100; -- Second iteration ( size = 100, lastCustomerId = 100 ) select * from CUSTOMERS where status = 'ACTIVE' and customer_id > 100 order by customer_id asc limit 100; -- Second iteration ( size = 100, lastCustomerId = 200 ) select * from CUSTOMERS where status = 'ACTIVE' and customer_id > 200 order by customer_id asc limit 100;
MICROIDEATION APP: Programming and tech topics explained as quick learning cards ( ideations ) .
We have launched our new mobile app for learning programming and other tech-based topics in under 30 seconds. The content is crafted by subject-matter-experts on the field and each topic is explained in 500 or fewer characters with examples and sample code. You can swipe for the next content or freeze and follow a particular topic. Each content is self-contained and complete with links to related ideations. You can get it free ( no registration required ) in the play store now. ![]()
In this method, as you can see, there is no offset argument for the limit keyword. The largest customer_id field in the result set is identified and we are requesting the next 100 entries greater than the last id field. Here if the id field is indexed field ( primary keys are always indexed), then we would be having negligible time spent on fetching and this would be constant irrespective of the number of records you have read so far.
Program logic using Peeking
Let’s see a program logic in spring boot where we apply this peeking method to retrieve the records for customers. We will be taking the following assumptions:
- CUSTOMERS table has got an auto-generated numeric id called customer_id.
- The records can be fetched in the ascending order of this id.
- We have a method of identifying the largest id in the returned result set.
CustomerRepository
We need to tweak the CustomerRepository to add a new method for fetching using peeking
interface CustomerRepository extends JpaRepository<Customer,Long> {
List<Customer> findByStatusAndCustomerIdGreaterThanOrderByCustomerIdAsc(String status, Long lastCusId,Pageable pageable);
}
You can see that we are still using Pageable, but the offset passed would be always 0 and hence it won’t have any effect on the performance.
CustomerProcessorService
Let’s see the service method where we will be using the peeking method to get the customers using the above repository method.
public class CustomerProcessorService {
public void processCustomers() {
List<Customer> customers = new ArrayList();
long lastCusId = 0;
int size = 100;
while ( true ) {
// Create a PageRequest object that will be passed as Pageable interface to repo
// Note that here we are setting 0 as the offset
PageRequest pageRequest = new PageRequest(0,size);
// Get the lastCusId
lastCusId = getLastCusId(customers);
// Get the data from the database
customers = customerRepository.findByStatusAndCustomerIdGreaterThanOrderByCustomerIdAsc('ACTIVE',lastCusId,pageRequest);
// Check if data is there
if ( customers == null || customers.isEmpty()) {
break;
}
// Do the processing
}
}
public Long getLastCusId(List<Customer> customers) {
// If passed entry is null or empty, return 0 ( This handles the first iteration case )
if ( customers == null || customers.isEmpty())
return 0l;
// Do the logic to sort the customers list by customer_id of each
// Customer object
// Return the last entry
return customers.get(customers.size() -1).getCustomerId();
}
}
We have done the following things in the processCustomers() method
- Initialized the initial list to empty ArrayList
- Create a PageRequest with 0 as offset and use size as provided
- Get the last customer id in the list ( Please implement the sorting logic for the List based on your field )
- Call the repository method to fetch the details based on the customer Id
- Check if any data returned and break if there is no more data
- Do the processing with the list of customers fetched.
This would start with 0 as the lastCusId and get the initial 100 records. In the next iteration, we will find the largest customer_id from the list and call the method again with that as the reference value. In all the iterations, the offset value is 0 as we are now ordering it by customer_id and limiting the values to entries larger than the previous list.
When you change the fetch logic to this method, you could see a tremendous improvement in the fetch performance.
Conclusion
We can see that the peek method is pretty easy to configure and if you are already using pagination, you can easily replace it with peeking. Just need to be careful about the following points
- There should be a numerical unique identifier for each record ( preferably a primary key )
- The result set should be ordered
- We should have the logic to sort and find the largest id in the retrieved list.
- There should be an index on the identifier field which you are using for peeking.
Please also note that this would improve the fetch time from the database, but there could be other things that slow down like subqueries being executed for fetching associated child entries of entities etc.
Also would like to point out that the size of the batch should be carefully chosen. There is no one-size-fits-all solution to this. You would need to try it out with different values to find the optimum value in your case. If there are many sub-queries or eager loading of child entities, I would suggest to keep it as 100 and then try increasing in batches of 100 to identify the sweet spot.
Let me know if you have any questions regarding the logic.
regards
S