RabbitMQ configuration for HA ( Queue Mirroring )
RabbitMQ is one of the most commonly used messaging brokers. The setup is fairly straightforward and there is abundant support available for different client languages and libraries. We have many RabbitMQ clusters deployed in our production environment. Due to the inherent simplicity of the setup, it is very easy to get carried away with the default values and forget about important tuning required for production. In this post, we will discuss on how we can enable high availability for the queues which is not enabled by default.
Clustering Vs High availability
When we have rabbitmq running in different nodes, we can cluster them together so that they can be managed as a whole. Most of the services, when clustered, will have a master and slaves setup and in case of a network partition or node unavailability, a subsequent node is selected as the master and the service will be uninterruptedly available. But the case with RabbitMQ is little different.
No Master Node in the cluster
That’s right, RabbitMQ does not have the concept of a master and slave nodes in a cluster. All the nodes in the cluster are treated independently but kept in communication so that the changes applied to the configuration are propagated to all the nodes.
Queue location
Another very important concept is that, by default, a queue will be storing all the messages in the node where it was created. So when a node dies, this will take down all the data in the non-durable queues defined in that node.
Queue Mirroring ( HA for Queue )
With the above points in mind, let’s see how we can have the data in the queue be replicated.
RabbitMQ achieves this by a method called Queue Mirroring. Basically, the queue is replicated to a different node based on some policy that we specify. Now the node where the queue was created is the master node for the queue and all the operations go through this. In case the master node is unavailable, the next available slave node with recent data is made master for the queue. Please note that the node is made master only for the queue and there is no master node for the cluster as such.
You can read more about queue mirroring in RabbitMQ Documentation
Enable Queue Mirroring in RabbitMQ
Enough of theory, let’s see how we can implement this in a RabbitMQ cluster for a particular queue , group of queues or for all the queues.
Adding a policy
Queue mirroring is applied to the queues based on a policy that we specify to the RabbitMQ cluster. The policy can be specified by the command line, using the REST API or my preferred method of adding via the rabbitmq management centre. We will be looking at the method of specifying the policy using the management centre.
Before we begin, let’s assume that we have a transient queue com.microideation.test.queue, the configuration would be as below. Please note that there is no policy set and the node where it resides is app-stage-1.
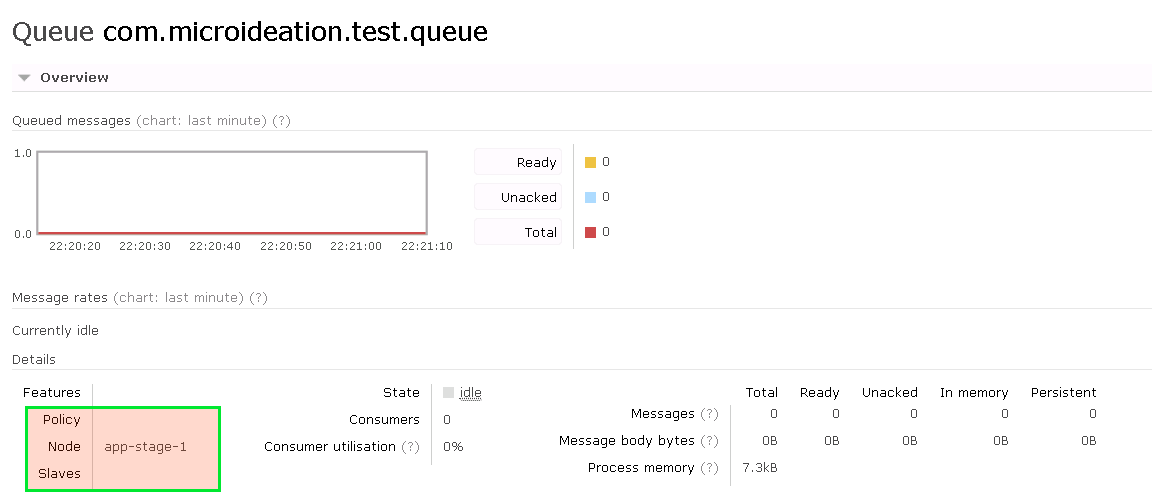
At this point, the Slaves section is empty. This means that if app-stage-1 goes down, the entire data in the queue is lost.
Adding policy to replicate queues starting with “com”
Goto the “Admin” Section of the management centre and then click on the “Policies” on the right side. This will list all the policies currently setup ( which should be empty if you are doing this for the first time ). Now follow the below steps to add a policy
- Click on ‘Add / Update a policy’
- Provide name as “ha-two-com-queues”
- Provide a pattern as “^com\.”
- Now we need to specify the definition of the policy.
- In the first definition, put key as “ha-mode” and value as “exactly”
- In the second definition ( which will be automatically added below ), put key “ha-params” and value as “2”. Select the type as “Number” from the dropdown next to the fields.
- In the third definition, put key as “ha-sync-mode” and value as “automatic”
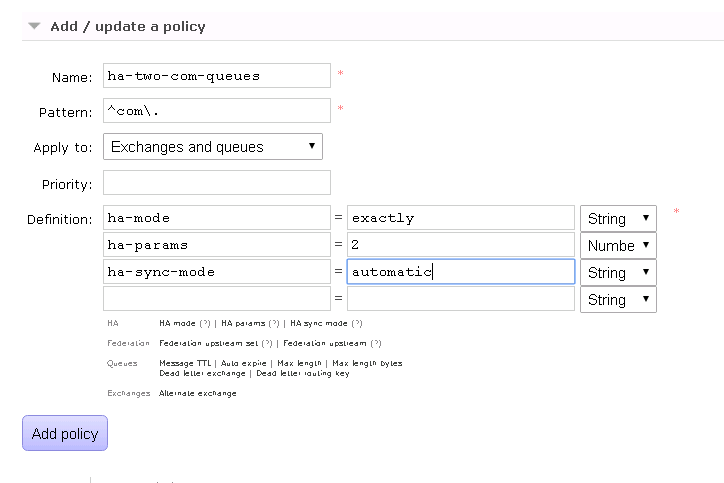
- Add the Policy ( Please note that all the values need to specified without the quotes )
Here we have specified policy and asked to apply it to queues starting with “com”. Our objective is to make sure that the queue is available in exactly 2 nodes in a cluster which is sync automatically. This is specified using the “ha-mode”, “ha-params” and “ha-sync-mode” fields.
If we want to have this policy applied to all the queues, we only need to change the pattern to “.*”
Queue characteristics after applying policy
Let’s go back to our queue at the management centre and see what has changed now. We can now see that the policy applied is the one we specified and now the Slaves has got value.
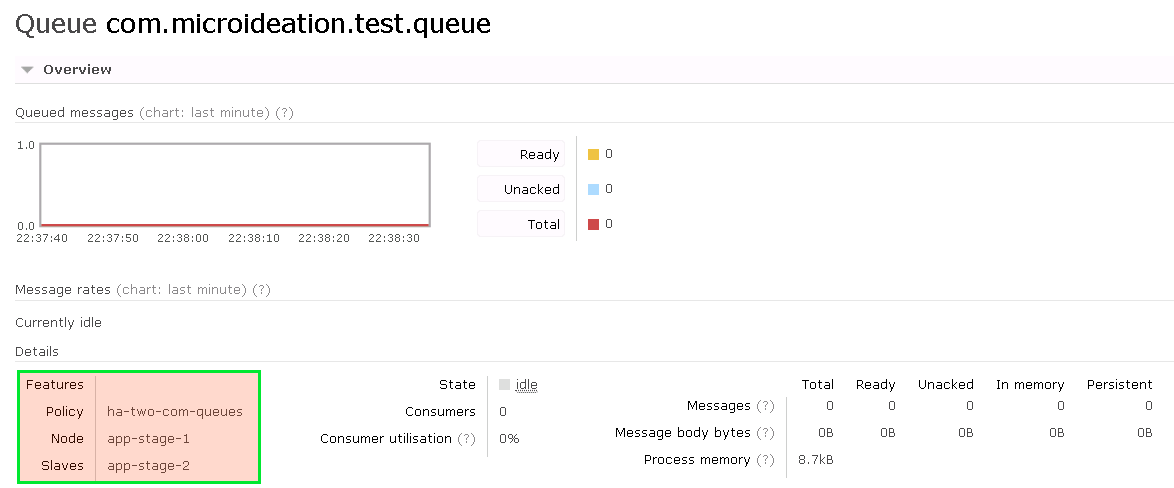
Now when the node app-stage-1 is down, the queue will still have the data available in the app-stage-2 and will take up the responsibility of serving the clients.
Conclusion
It is imperative to make sure that the queues that we have in the production are replicated properly to ensure the availability of data in the case of server issues. Also, please note that the replication does have a network cost in the cluster. So it should be applied wisely. We can use the policies to apply the mirroring to only particular queues that are critical to the operations.
Let me know your thoughts and queries on the same.
regards
S




